1. Introduction
Why ML Coding Interviews Matter
Landing a machine learning (ML) role at top tech companies like Google, Amazon, and Meta requires more than knowing ML algorithms—you must also excel in Crack the Coding Interview. These tests evaluate your ability to implement core algorithms, optimize model performance, and solve real-world ML problems under time constraints.
Common Fears & Misconceptions About ML Coding Interviews
Many candidates are intimidated by ML coding interviews because they appear highly technical and involve advanced math, coding
skills, and system design.
“I’m not good at
coding.”
“What if I
forget
key ML concepts?”
“How much depth
do I need to cover?”
What This Blog Will Cover
We’ll break down the ML coding interview process, cover core topics, provide real-world examples, and show how
InterviewNode can help you ace your next interview.
2. Understanding ML Coding
Interviews
What Is an ML Coding
Interview?
An ML coding interview tests your ability to implement core machine learning algorithms, optimize model performance, and solve real-world
ML-related coding challenges. Unlike standard coding interviews focused solely on algorithms and data
structures, ML coding interviews require a blend of software engineering skills, ML domain knowledge, and
coding proficiency.
These interviews typically involve coding tasks related to data preprocessing, model training, evaluation metrics, and system-level
implementation of ML solutions.
Why Companies Conduct These Interviews
ML engineers are expected to integrate models into production environments, optimize ML pipelines, and ensure models scale efficiently.
Companies conduct ML coding interviews to assess:
Algorithmic Proficiency: Ability to implement algorithms from scratch.
Coding Skills: Writing clean, modular, and efficient code.
Problem-Solving Ability: Applying ML techniques to practical challenges.
System Design Knowledge: Understanding of system architecture, model deployment, and
scalability.
What Happens During an ML
Coding Interview?
Introduction: A brief discussion of your experience and background.
Problem Statement: The interviewer presents an ML-related coding challenge.
Coding Session: You implement the solution in a shared code environment.
Q&A and Discussion: You explain your approach, discuss trade-offs, and suggest
improvements.
Feedback and Next Steps: The interviewer provides feedback or transitions to another question.
Types of Questions Asked
ML coding interviews usually focus on these categories:
1. Algorithm Implementation
Implement ML algorithms such as linear regression, logistic regression, k-means clustering, or decision trees from
scratch.
Example: “Implement logistic regression with gradient descent.”
2. Data Preprocessing Tasks
Data cleaning, feature scaling, encoding categorical data, and handling missing values.
Example: “Clean a dataset by removing duplicates and scaling numeric features.”
3. Model Training and Evaluation
Train, evaluate, and tune models using frameworks like scikit-learn, TensorFlow, or PyTorch.
Example: “Train a decision tree classifier and evaluate it using precision, recall, and F1 score.”
4. ML System Design
Design scalable ML pipelines, data ingestion systems, and APIs for model serving.
Example: “Design an end-to-end ML pipeline for real-time fraud detection.”
5. Optimization Problems
Tune hyperparameters, optimize model performance, and reduce inference time.
Example: “Optimize a neural network for faster inference on edge devices.”
What Interviewers Look For: Core Skills Assessed
1. Coding Efficiency
Can you write well-structured, efficient, and readable code?
Do you follow software engineering best practices like modularization and code reuse?
2. Algorithmic Knowledge
Are you familiar with fundamental ML algorithms like linear regression, decision trees, and clustering methods?
Do you understand how and when to apply specific algorithms?
3. ML-Specific Problem Solving
Can you solve ML tasks like feature engineering, model training, and deployment?
Are you capable of managing end-to-end ML workflows, including data processing and evaluation?
4. Mathematical Rigor
Do you understand the underlying mathematics behind ML algorithms?
Can you explain concepts like gradient descent, loss functions, and probability distributions?
5. Communication and Collaboration
Can you clearly explain your approach and reasoning?
Do you respond well to feedback and adapt your solution accordingly?
How to Approach ML Coding Interviews
Understand the Problem: Clarify requirements and expected outputs.
Plan the Solution: Break the task into smaller components.
Write Clean Code: Implement the solution while explaining your approach.
Test Thoroughly: Test edge cases and validate correctness.
Discuss Improvements: Suggest alternative approaches, optimizations, and trade-offs.
Example Interview Flow
Problem Statement:
“Build a recommendation system using collaborative filtering.”
Candidate Approach:
Clarify data format and evaluation metrics.
Implement data preprocessing (cleaning, encoding, splitting).
Implement collaborative filtering from scratch using matrix factorization.
Evaluate the system using RMSE and discuss potential improvements.
3. Core Concepts to Master for ML Coding Interviews
1. Data Preprocessing and Feature Engineering
Data preprocessing is the foundation of any ML pipeline. Poor data quality leads to unreliable models, making this a key area for ML
coding interviews.
Data Cleaning
Handling Missing Values: Missing values can negatively affect model performance. Use techniques like
mean, median, or mode imputation for numeric data. For more complex scenarios, consider advanced
approaches like k-nearest neighbors (KNN) imputation or predictive models to fill in missing
data.
Removing Duplicates: Duplicate records can cause bias in the model and distort evaluation
metrics. Identify and remove duplicates using unique keys or by comparing row content.
Outlier Detection: Outliers can skew model predictions, especially in regression tasks. Use
statistical methods like z-score normalization, IQR-based filtering, or isolation forests to detect
and remove anomalous data points.
Feature Scaling
Standardization (Z-Score): Standardization centers the data by subtracting the mean and scaling to unit
variance. This is essential for algorithms like logistic regression and neural networks that are
sensitive to feature magnitudes.
Min-Max Scaling: This technique scales data into a specified range, usually between 0 and 1.
It’s useful for models requiring bounded input, like K-Nearest Neighbors and support vector
machines.
Feature Encoding
One-Hot Encoding: Convert categorical variables into binary vectors, creating new columns for
each category. This technique is useful for algorithms that can’t handle categorical data directly,
like logistic regression and neural networks.
Label Encoding: Assign numeric labels to ordered categories. Use it when categories have an
implicit rank (e.g., low, medium, high). Be cautious of models interpreting numeric labels as
continuous values.
Dimensionality Reduction
Principal Component Analysis (PCA): PCA reduces feature dimensions by projecting data into a
lower-dimensional space while retaining maximum variance. It helps reduce overfitting and speeds up
model training.
t-SNE & UMAP: These techniques are ideal for data visualization and exploratory data analysis,
especially for high-dimensional datasets like embeddings from NLP models.
Example: “Given a dataset of customer transactions, preprocess it by handling
missing values, scaling numeric features, encoding categorical variables, and reducing dimensionality with
PCA.”
2. Core Machine Learning Algorithms
Understanding core ML
algorithms is crucial. You’ll be expected to implement some from scratch.
Supervised Learning
Linear Regression
Concept: Model the linear relationship between dependent and
independent variables using a straight line. This algorithm assumes a continuous relationship and
minimizes the mean squared error.
Key Equation: $y = \beta_0 + \beta_1x$
Implementation: Use gradient descent or ordinary least squares to
estimate coefficients.
Logistic Regression
Concept: Used for binary classification, logistic regression applies
the sigmoid function to output probabilities. It predicts class membership based on linear
features.
Key Equation: $P(y=1) = \frac{1}{1+e^{-z}}$
Application: Spam detection, credit card fraud detection, and binary
medical diagnoses.
Decision Trees & Random Forests
Concept: Decision trees split data into subgroups using if-else
rules, creating branches based on feature thresholds. Random forests aggregate multiple trees to
reduce variance and improve accuracy.
Important Metrics: Use Gini impurity or entropy for decision-making splits.
Unsupervised Learning
K-Means Clustering
Concept: Partition data into clusters by minimizing the distance
between data points and centroids. It is effective for tasks like customer segmentation and anomaly
detection.
Optimization: Use the elbow method to determine the optimal number of
clusters.
Principal Component Analysis (PCA)
Concept: Reduce feature dimensionality by transforming correlated
features into principal components. This simplifies the dataset while retaining important
variance.
Use Case: Visualizing multi-dimensional datasets or speeding up ML algorithms.
Gaussian Mixture Models (GMM)
Concept: Apply probabilistic models assuming data points are
generated from Gaussian distributions. Each component has a probability distribution defining
cluster membership.
Application: Anomaly detection and density estimation.
Neural Networks
Feedforward Neural Networks
Concept: Use fully connected layers to model complex patterns in
data. The network learns weights and biases using backpropagation and gradient descent.
Implementation: Implement layers, activation functions, and
optimization from scratch.
Convolutional
Neural Networks (CNNs)
Use Case: Apply CNNs for image classification tasks, detecting objects, and image
segmentation. Use convolutional and pooling layers for feature extraction and dimensionality
reduction.
Important Layers: Convolutional, pooling, fully connected, and softmax layers.
Recurrent Neural Networks (RNNs)
Use Case: Handle sequential data such as time-series data, text, or speech recognition. Use
specialized RNN variants like LSTMs or GRUs to manage long-term dependencies and prevent vanishing
gradients.
Example: “Implement a decision
tree from scratch, evaluate its performance
using precision, recall, and discuss improvements with ensemble methods like random forests.”
4. Step-by-Step Guide to Solving an ML Coding Interview Question
Example Question: Build a Sentiment Analysis Model for Movie Reviews
Let’s walk through this example problem to understand the approach to an ML coding interview in a detailed and structured
manner.
Step 1: Clarify Requirements
Before writing any code, start by clarifying all relevant details about the problem. This helps ensure that your solution meets the
business requirements.
Input Format: Determine how movie reviews will be provided—plain text, CSV, JSON, or a
database connection. This will affect how data ingestion is performed.
Output Format: Clarify whether the output should be binary (Positive/Negative) or a
multi-class rating system (e.g., 1-5 stars).
Evaluation Metrics: Ask how the model’s performance will be evaluated. Metrics like accuracy, F1
score, precision, recall, and AUC-ROC are common for classification tasks.
Data Size Consideration: Clarify whether the dataset will fit in memory or require distributed
processing using frameworks like Apache Spark.
Example Clarification Response: "We’ll use CSV files containing text reviews and binary labels (Positive/Negative).
The evaluation metric will be F1 score to balance precision and recall, ensuring fair evaluation even with
imbalanced datasets."
Step 2: Data Preprocessing
Data preprocessing is a critical step to ensure that your model can learn meaningful patterns from the data.
Text Tokenization: Use libraries like NLTK or SpaCy to tokenize text into words or n-grams,
allowing the model to understand word patterns.
Lowercasing & Stopword Removal: Convert all text to lowercase and remove common stopwords like "the,"
"and," and "is" to reduce noise and focus on relevant terms.
Lemmatization/Stemming: Standardize words to their base form (e.g.,
"running" → "run") using lemmatization techniques for consistency.
Punctuation Removal: Remove special characters and symbols that don’t contribute to model
learning.
TF-IDF Vectorization: Use TF-IDF to transform text into numerical vectors that capture word
importance.

Step 3: Model Selection and Training
Selecting the appropriate model is essential based on the complexity of the problem and available resources.
Model Choice: Start with a simple baseline model like Logistic Regression for quick testing.
If deeper learning is needed, use RNNs, LSTMs, or BERT-based Transformers.
Training Pipeline: Split the data into train and test sets using train_test_split. Use
cross-validation with GridSearchCV for hyperparameter tuning.
Model Fitting: Train the model using the cleaned TF-IDF matrix generated during
preprocessing.
Regularization: Use L2 regularization (C parameter in Logistic
Regression) to prevent overfitting.
Step 4: Model Evaluation
Model evaluation helps determine whether the solution is ready for deployment or requires further improvement.
Accuracy: Measures the overall correctness of predictions but can be
misleading on imbalanced datasets.
Precision & Recall: Precision measures how many predicted positives were correct, while recall
measures how many actual positives were captured.
F1 Score: Use the F1 score for a balanced evaluation of precision and recall.
Confusion Matrix: Visualize prediction performance, showing true positives, true negatives, false
positives, and false negatives.
Cross-Validation: Use k-fold cross-validation to ensure consistent
model performance across multiple data splits.
Step 5: Model Deployment
After achieving acceptable
performance, deploy the model using a web API service.
Flask/FastAPI: Create a REST API to serve predictions, allowing
integration with web and mobile applications.
Dockerization: Use Docker to containerize the API for portability
across different environments.
Cloud Deployment: Deploy the model on cloud services like AWS Lambda, Google Cloud, or Azure
App Services for scalability.

Step 6: Edge Cases and Improvements
Address potential challenges
and propose enhancements for long-term system stability:
Cold Start Problem: Precompute recommendations for new users or products to reduce latency.
Model Bias: Ensure the training dataset is balanced across different sentiment classes to
avoid bias.
Data Drift Monitoring: Set up tools like Prometheus and Grafana to track prediction performance
and trigger retraining when accuracy drops.
Advanced Models: Consider switching to a Transformer-based model like BERT or DistilBERT for
better context understanding and nuanced sentiment predictions.
Performance Optimization: Use ONNX or TensorFlow Lite to optimize model inference for real-time
systems.
By following this in-depth approach, you’ll be able to solve even the most complex ML coding interview questions while demonstrating
clear thinking, technical expertise, and a strong understanding of real-world implementations. Let me know
if you'd like further elaboration on specific steps!
5. Common Mistakes to Avoid
Machine learning coding interviews can be challenging due to their technical depth and open-ended nature. Many candidates struggle
because they overlook important areas or fall into common traps. Here’s a detailed breakdown of typical
mistakes to avoid and strategies for success.
1. Focusing Too Much on ML Theory Without Coding
The Mistake:
Candidates often spend too
much time explaining ML concepts like gradient descent, overfitting, or neural network architectures,
assuming the interviewer wants a theoretical lecture.
Why It’s a Problem:
While theory matters, coding interviews are meant to test your implementation skills. Interviewers expect working code, not textbook
explanations. Focusing too much on theory can waste valuable time and leave the interviewer uncertain about
your coding abilities.
How to Avoid:
Limit theoretical discussions to justifying your design choices.
Clearly explain why you chose a particular algorithm while coding it out.
Be concise and practical.
Use theory only when needed.
Example: “I’m selecting Logistic
Regression because it’s interpretable and
performs well on binary classification tasks. Let me implement it now.”
2. Ignoring Data Preprocessing and Cleaning
The Mistake:
Skipping data cleaning steps like handling missing values, normalizing features, or removing duplicates.
Why It’s a Problem:
Raw data is rarely clean. Ignoring preprocessing can cause models to underperform, leading to failed predictions. Missing values,
duplicates, and inconsistent data formats can cause significant issues during training and
evaluation.
How to Avoid:
Always inspect the dataset first for inconsistencies.
Mention how you would clean the data even if preprocessing is out of scope.
Discuss specific techniques such as imputing missing values, scaling features, or encoding categorical
variables.
Example: “I’ll remove missing
values, standardize numeric features, and apply
one-hot encoding to categorical variables to ensure compatibility with ML models.”
3. Poor Feature Engineering
The Mistake:
Relying solely on raw input features without extracting meaningful features.
Why It’s a Problem:
Good models need well-engineered features. Ignoring this step leads to reduced predictive power. Without relevant features,
even the most advanced algorithms will fail to make accurate predictions.
How to Avoid:
Discuss feature extraction strategies for numerical, categorical, and text data.
Use domain knowledge to engineer relevant features.
Mention specific techniques such as polynomial feature creation, TF-IDF vectorization, and feature selection.
Example: “For sentiment
analysis, I’ll use TF-IDF to capture word importance
and extract sentiment scores using a lexicon-based approach.”
4. Overlooking Model Evaluation Metrics
The Mistake:
Assuming accuracy is the only evaluation metric, regardless of the task.
Why It’s a Problem:
Accuracy is misleading for imbalanced datasets. Using improper metrics can give a false sense of model performance, causing poor
decisions in model selection.
How to Avoid:
Use relevant metrics like F1 score, precision, recall, and ROC-AUC.
Explain why you selected each metric based on the business use case.
Compare multiple metrics to get a comprehensive view of model performance.
Example: “Since we are dealing
with an imbalanced dataset, I’ll use the F1
score to balance precision and recall, ensuring robust evaluation.”
5. Using the Wrong Model for the Problem
The Mistake:
Choosing a complex model without considering simpler, more interpretable alternatives.
Why It’s a Problem:
Overcomplicating the model adds unnecessary complexity, making deployment and maintenance harder. Simpler models are easier to debug
and interpret.
How to Avoid:
Start with a simple baseline model.
Gradually increase complexity if needed.
Choose interpretable models when the use case requires explainability.
Example: “I’ll start with a Logistic Regression model. If the results are
insufficient, I’ll explore Random Forest or XGBoost for better predictive power.”
6. Ignoring Hyperparameter Tuning
The Mistake:
Using default hyperparameters without optimization.
Why It’s a Problem:
Suboptimal hyperparameters can result in poor performance and missed improvement opportunities. Many algorithms require fine-tuning to
reach peak performance.
How to Avoid:
Use GridSearchCV or RandomizedSearchCV for systematic tuning.
Mention specific parameters to tune, like C in Logistic Regression or max_depth in Random Forest.
Consider automating hyperparameter tuning using frameworks like Optuna or Hyperopt.
Example: “I’ll perform GridSearchCV to optimize the regularization strength
and solver for Logistic Regression.”
7. Forgetting to Validate and Test Models Properly
The Mistake:
Skipping validation steps like cross-validation or failing to use a proper test set.
Why It’s a Problem:
Training performance can be misleading without validation. This results in overfitting and unreliable results when the model is exposed
to unseen data.
How to Avoid:
Use train-test splits and k-fold cross-validation.
Discuss the importance of data separation to prevent data leakage.
Validate models using appropriate evaluation sets.
Example: “I’ll split the data
into train, validation, and test sets to
evaluate the model on unseen data, ensuring robust performance measurement.”
8. Failing to Explain Code Clearly
The Mistake:
Writing code silently without explaining the rationale behind decisions.
Why It’s a Problem:
Interviewers assess your communication and problem-solving process, not just the final code. Lack of explanation makes it difficult for interviewers to follow your thought process.
How to Avoid:
Narrate your thought process while coding.
Explain design decisions, trade-offs, and expected outputs.
Discuss alternative solutions if applicable.
Example: “I’m creating a TF-IDF vectorizer to convert text into numerical
features, which Logistic Regression can use effectively for classification.”
9. Ignoring Edge Cases and Exceptions
The Mistake:
Failing to account for rare or edge cases like missing data, null values, or unexpected inputs.
Why It’s a Problem:
ML systems break when encountering unexpected scenarios, leading to unreliable predictions and potential system failures.
How to Avoid:
Validate input data.
Use exception handling and assertions.
Test edge cases as part of the evaluation process.
Example: “I’ll add input validation and raise errors if the review text is
empty or contains non-alphabetic characters.”
10. Not Considering Model Deployment and Monitoring
The Mistake:
Ignoring how the trained model will be deployed and monitored.
Why It’s a Problem:
A successful interview goes beyond training models. Real-world systems require deployment, monitoring, and updates to adapt to changing
data.
How to Avoid:
Discuss deployment options like Flask APIs, Docker containers, and cloud services.
Mention monitoring tools like Prometheus and Grafana.
Describe retraining strategies to maintain performance.
Example: “After training, I’ll deploy the model using Flask and containerize
it with Docker. Monitoring will be set up using Prometheus and Grafana.”
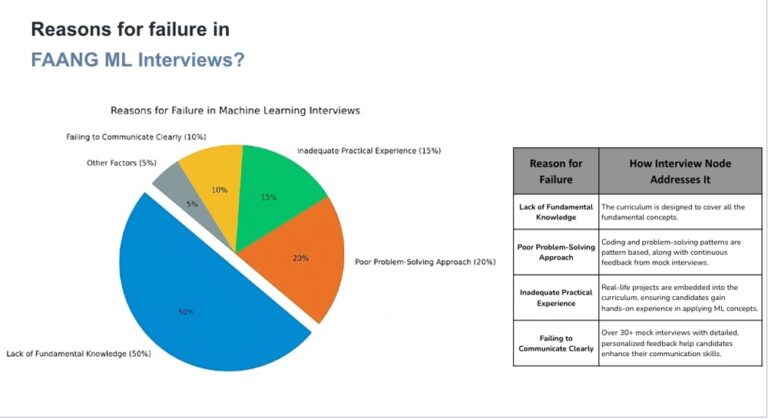
6. How InterviewNode Can Help You
Mastering ML coding interviews requires more than just theoretical knowledge—you need hands-on practice, expert feedback, and
real-world challenges. This is where InterviewNode shines by providing a comprehensive
interview preparation platform designed specifically for ML engineers.
1. Expert-Led Mock Interviews
At InterviewNode, you’ll work directly with industry experts from companies like Google, Amazon, and Meta. These professionals have
extensive experience conducting ML coding interviews and know exactly what top-tier companies expect from
candidates.
How It Works:
One-on-One Sessions: Get personalized mock interviews with senior ML engineers.
Live Coding Assessments: Practice coding problems in real-time while receiving expert
feedback.
Targeted Question Bank: Tackle questions that mirror actual ML coding interviews.
Example:
A candidate preparing for an ML engineer role at a FAANG company gets personalized coaching from a former Google interviewer. They
receive instant feedback on their approach to building a sentiment analysis model, improving model
evaluation techniques, and optimizing training pipelines.
2. In-Depth Feedback and Actionable Insights
After each mock interview, you’ll receive detailed feedback on your performance. Our experts break down your strengths and areas for
improvement with actionable guidance.
What You’ll Get:
Code Reviews: Review your implementation, algorithm choices, and coding efficiency.
System Design Assessments: Get feedback on system architecture and design trade-offs.
Interview Skills Evaluation: Learn how to clearly explain your solutions and handle challenging
follow-up questions.
Example:
After completing a mock interview on building a recommendation system, a candidate is advised to improve how they explain trade-offs
between collaborative filtering and content-based models. This targeted feedback helps the candidate refine
their responses and coding practices.
3. Real-World Machine Learning Projects
We believe the best way to learn is through practice. At InterviewNode, you’ll work on real-world projects designed to simulate the
kinds of problems you’d encounter in industry.
Project-Based Learning:
End-to-End ML Pipelines: Build complete ML systems from data ingestion to model deployment.
Advanced Topics: Tackle real-world challenges like fraud detection, recommendation systems, and
computer vision projects.
Portfolio Development: Showcase your work by building a portfolio of production-ready
projects.
Example:
A candidate builds a fraud detection model, covering data cleaning, feature engineering, model tuning, and cloud deployment using AWS
Lambda and Docker. Their work is reviewed by an industry expert who provides practical suggestions on
optimizing inference latency.
4. Comprehensive Interview Resources
InterviewNode offers an extensive repository of learning materials designed to complement your interview preparation.
What’s Included:
Exclusive Interview Guides: Detailed tutorials on coding problems, system design, and ML project
implementation.
Video Tutorials: Step-by-step walkthroughs of ML coding problems and real-world project
breakdowns.
Cheat Sheets and Frameworks: Downloadable quick-reference guides for common ML algorithms, evaluation
metrics, and system design principles.
Example Resource:
A comprehensive guide on
designing a scalable recommendation system includes system architecture diagrams, evaluation metric
explanations, and best practices for optimizing real-time model inference.
5. Personalized Learning Plans
Every learner is different. At InterviewNode, we customize your interview preparation based on your specific goals and current skill
level.
How It Works:
Initial Skill Assessment: Take a system design diagnostic interview to assess your current skill
level.
Custom Roadmap: Receive a personalized learning path based on your strengths, weaknesses, and
target job roles.
Progress Tracking: Monitor improvements with performance metrics and track your
milestones.
Example:
After an initial assessment, an aspiring ML engineer is guided through intermediate ML concepts like hyperparameter tuning, deep learning
architectures, and scalable model deployment strategies.
6. Why InterviewNode Stands Out
What sets InterviewNode apart from other platforms is our outcome-focused approach. We combine real-world expertise, personalized
coaching, and an extensive interview prep curriculum to ensure your success.
Key Advantages:
Expert-Led Training: Learn from practicing ML engineers with real industry experience.
Hands-On Learning: Work on real-world projects and build production-level systems.
Proven Curriculum: Trusted by hundreds of successful ML engineers worldwide.
Call to Action:
Ready to ace your next ML coding interview and land your dream job? Join InterviewNode today and experience the
best-in-class interview preparation designed specifically for machine learning engineers.